“Namespace 做隔离,Cgroups 做限制,rootfs 做文件系统”,为什么 Kubernetes 项目又突然搞出一个 Pod 来呢?
先回顾下:容器的本质到底是什么?
容器实际上是一个视图被隔离,资源受限的进程。
PID =1 的进程就是应用本身。
管理虚拟机 ==> 管理基础设施
管理容器 ==> 直接管理应用本身
Kubernetes:云时代的操作系统,容器镜像就是这个系统里的软件安装包。
进程组
在一个真正的操作系统里,进程并不是“孤苦伶仃”地独自运行的,而是以进程组的方式,“有原则地”组织在一起。
1 | $ pstree -p |
Helloworld 进程由 4 个线程组成,共享进程资源,协作完成 Helloworld程序的职责。如何在容器里面将 Helloworld 跑起来呢?
1、在docker容器里面,启动这4个进程
疑问:容器中 PID=1 的进程就是应用本身(如main进程),谁来管理其它3个进程呢?
由于容器实际上是一个“单进程”模型,所以如果你在容器里启动多个进程,只有一个可以作为 PID=1 的进程,而这时候,如果这个 PID=1 的进程挂了,或者说失败退出了,那么其他三个进程就会自然而然的成为孤儿,没有人能够管理它们,没有人能够回收它们的资源,这是一个非常不好的情况。
2、容器的 PID=1 进程改成 systemd
将会导致另外一个问题:管理容器 = 管理 systemd != 管理应用本身了。实际上没办法直接管理我的应用了(因为我的应用被 systemd 给接管了),那么这个时候应用状态的生命周期就不等于容器生命周期。那么接下来,这个应用是不是退出了?是不是 fail 了?是不是出现异常失败了?这个管理模型是很复杂的。
就是说现在有四个职责不同、相互协作的进程,需要放在容器里去运行,在 Kubernetes 里面并不会把它们放到一个容器里,因为这里会遇到上述两个问题。那么在 Kubernetes 里会怎么去做呢?
Pod = “进程组”
在 kubernetes 里面,Pod 实际上正是 kubernetes 项目为你抽象出来的一个可以类比为”进程组“的概念。
把四个独立的进程分别用 4 个独立的容器启动起来,然后把它们定义在一个 Pod 里面,4个容器共享 Pod 的资源。
Pod 在 Kubernetes 里面只是一个逻辑单位,没有一个真实的东西对应说这个就是 Pod,真正起来在物理上存在的东西,就是 4 个容器。
Pod 是 Kubernetes 分配资源的一个单位,因为里面的容器要共享某些资源,所以 Pod 也必须是 Kubernetes 的原子调度单位。
为什么 Pod 必须是原子调度单位?
举例:假如现在有两个容器,它们是紧密协作的,所以它们应该被部署在一个 Pod 里面。
- App,业务容器,写日志文件;
- LogCollector,把 App 容器写的日志文件转发到后端的 ElasticSearch 中。
资源需求:
- App:1G 内存,
- LogCollector: 0.5G 内存
当前集群环境的可用内存:
- Node_A:1.25G 内存,
- Node_B:2G 内存。
如果调度器先把 App 调度到了 Node_A 上面,会怎么样呢?
Task co-scheduling 问题
这是一个典型的 成组调度 失败的例子,业内提供的解决方案:
- Mesos:资源囤积(resource hoarding)
- 即当所有设置了 Affinity 约束的任务都达到时,才开始统一调度。
- 问题:调度效率不高和死锁。
- Google Omega:乐观调度
- 先调度,不管冲突,同时设置一个精妙的回滚机制在出现冲突后来解决问题。
- 实现机制非常复杂。
- Kubernates: Pod
- App 容器和 LogCollector 容器一定是属于一个 Pod 的,它们在调度时必然是以一个 Pod 为单位进行调度
再次理解 Pod
Pod 里面的容器是 超亲密关系
亲密关系 –> 调度解决:
- 两个应用需要运行在同一台宿主机上
超亲密关系 –> Pod 解决:
- 会发生直接的文件交换;
- 使用 localhost 或者本地的 Socket 进行通信;
- 会发生非常频繁的 RPC 调用;
- 会共享某些 Linux Namespace,比如一个容器需要加入另一个容器的 Network Namespace
Pod 的实现机制
Pod 要解决的问题:
如何让一个 Pod 里的多个容器之间最高效共享某些资源和数据,因为容器之间原本被 Namespce 和 cgroups 隔离开。
具体的解法分为两个部分:
共享网络
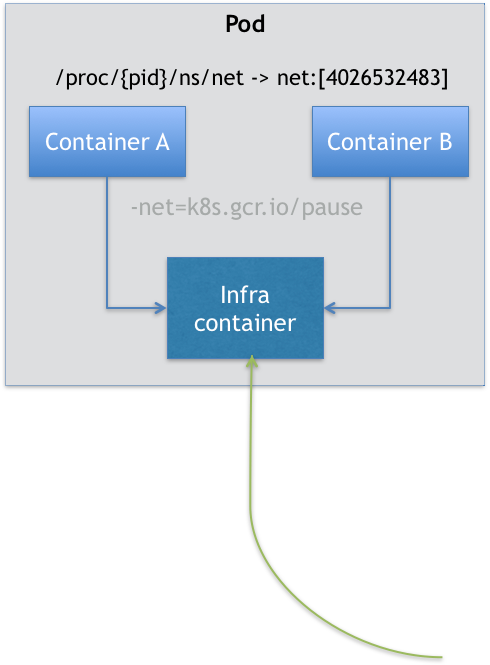
Kubernetes 项目里,Pod 的实现需要使用一个中间容器:Infra 容器。
- 在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。
- Infra 容器占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:
k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有100~200 KB左右。 - 用户容器可以加入到 Infra 容器的 Network Namespace 当中。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 容器A和B通过 Infra Container 的方式共享同一个 Network Namespace
- 直接使用 localhost 通信
- 看到的网络设备跟 Infra 容器看到的完全一样
- 一个Pod只有一个IP地址,也就是这个Pod的 Network Namespace 对应的IP地址,
- 所有网络资源 Pod 只有一份,所有容器共享
- Pod 的生命周期跟 Infra 容器一致,而与容器A和B无关
共享存储
shared-data 对应在宿主机上的目录会被绑定挂载进容器当中。
只要把所有 Volume 的定义都设计在 Pod 层级即可。这样,一个 Volume 对应的宿主机目录对于 Pod 来说就只有一个,Pod 里的容器只要声明挂载这个 Volume,就一定可以共享这个 Volume 对应的宿主机目录。
1 |
|
在这个例子中,debian-container 和 nginx-container 都声明挂载了 shared-data 这个 Volume。而 shared-data 是 hostPath 类型。所以,它对应在宿主机上的目录就是:/data。而这个目录,其实就被同时绑定挂载进了上述两个容器当中。
这就是为什么,
nginx-container可以从它的/usr/share/nginx/html目录中,读取到debian-container生成的index.html文件的原因。
Pod 这种“超亲密关系”容器的设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
为了能够掌握这种思考方式,你就应该尽量尝试使用它来描述一些用单个容器难以解决的问题。
容器设计模式
举例:我现在要发布一个 JAVA 应用,将一个 WAR 包放到 Tomcat 的 web APP 目录下面运气起来,该怎么去做发布?
- 方法一:把WAR包和Tomcat打包进一个镜像
- 无论是WAR包和Tomcat更新都需要重新制作镜像
- 方法二:镜像里只打包Tomcat。使用数据卷(hostPath)从宿主机将WAR包挂载进Tomcat容器
- 需要维护一套分布式存储系统
有没有更加通用的方法?哪怕在本地 Kubernetes 上,没有分布式存储的情况下也能用、能玩、能发布。
我们可以把 WAR 包和 Tomcat 分别做成镜像,然后把它们作为一个 Pod 里的两个容器“组合”在一起。这个 Pod 的配置文件如下所示:
1 |
|
在 Pod 中,所有 Init Container 定义的容器,都会比 spec.containers 定义的用户容器先启动。并且,Init Container 容器会按顺序逐一启动,而直到它们都启动并且退出了,用户容器才会启动。
在我们的这个应用 Pod 中,Tomcat 容器是我们要使用的主容器,而 WAR 包容器的存在,只是为了给它提供一个 WAR 包而已。所以,我们用 Init Container 的方式优先运行 WAR 包容器,扮演了一个 sidecar 的角色。
容器设计模式:Sidecar
通过在 Pod 里定义专门容器,来执行主业务容器需要的辅助工作。
- 需要SSH进去执行的脚本
- 日志收集
- Debug 应用
- 应用监控
优势:
- 将辅助功能同主业务容器解耦,实现独立发布和能力复用。
总结
- Pod 是 Kubernetes 项目里实现“容器设计模式”的核心机制;
- 容器设计模式是 Kubernetes 进行复杂应用编排的基础;
- 所有设计模式的本质都是:解耦和重用。
将传统应用架构迁移到云的核心思想是:分析应用组成(组件、进程),将其拆分成松耦合的容器(以容器镜像方式分发),利用 Init Container 来解决启动顺序和依赖关系。
“上云”工作的完成,最终还是要靠深入理解容器的本质,即:进程。
相反的,如果强行把整个应用塞到一个容器里,甚至不惜使用 Docker In Docker 这种在生产环境中后患无穷的解决方案,恐怕最后往往会得不偿失。强烈建议你逐渐采用容器设计模式的思想对富容器进行解耦,将它们拆分成多个容器组成一个 Pod。
