对于 Gopher 来说,掌握 Go 语言的协程调度机制是走向高级工程师的必由之路。

Golang「调度器」的由来?
单进程时代
我们知道,一切的软件都是跑在操作系统上,真正用来干活(计算)的是CPU。早期的操作系统每个程序就是一个进程,直到一个程序运行完,才能进行下一个进程。
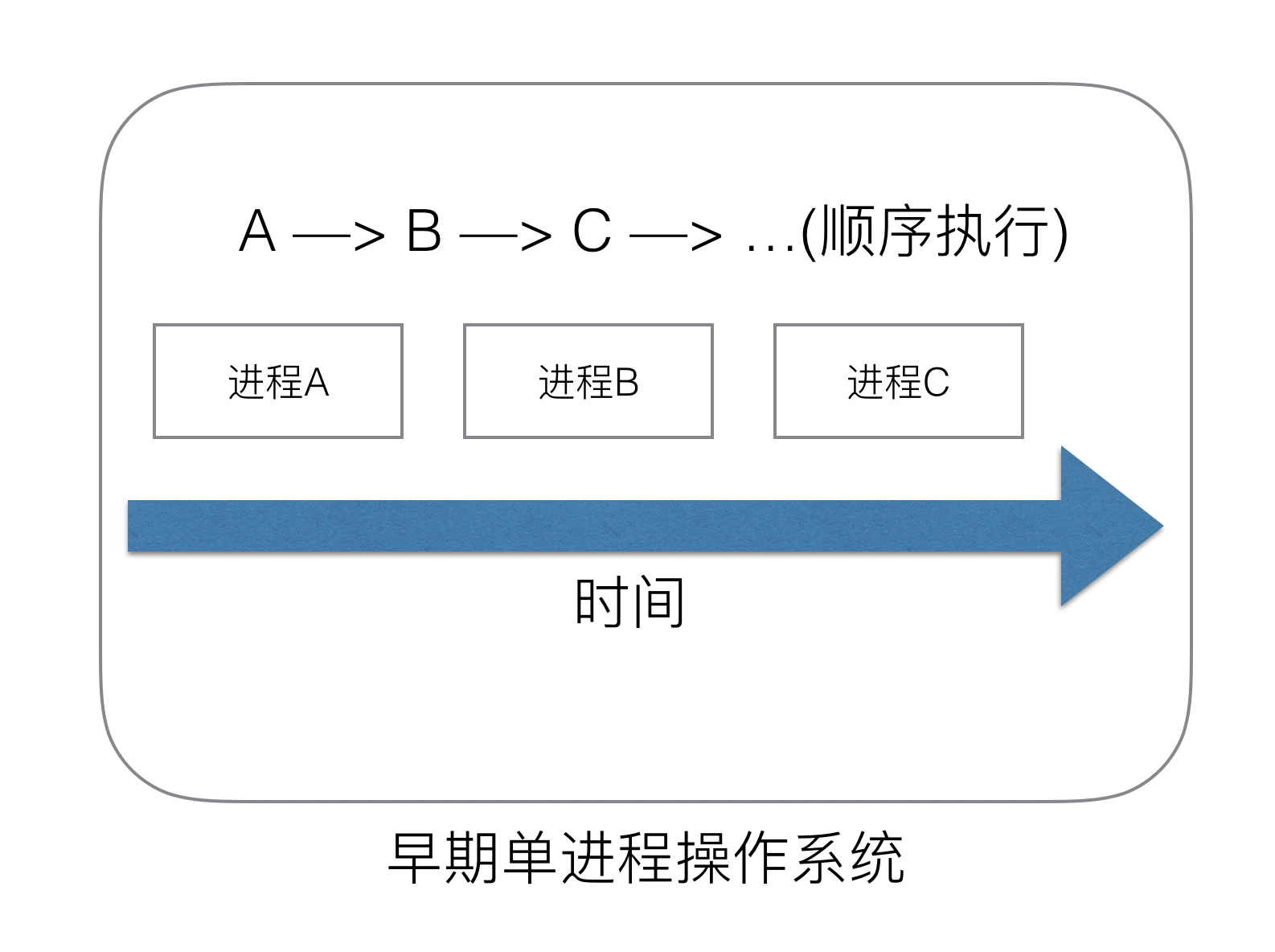
“单进程时代”,一切的程序只能串行发生,面临2个问题:
单一的执行流程,计算机只能一个任务一个任务处理。
进程阻塞所带来的CPU时间浪费。
多进程/线程时代
多进程并发,当一个进程阻塞的时候,切换到另外等待执行的进程,CPU 调度算法可以保证在运行的进程都可以被分配到 CPU 的运行时间片这样就能尽量把CPU利用起来,避免 CPU 资源浪费。
但新的问题就又出现了,进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间,CPU虽然利用起来了,但如果进程过多,CPU有很大的一部分都被用来进行进程调度了。
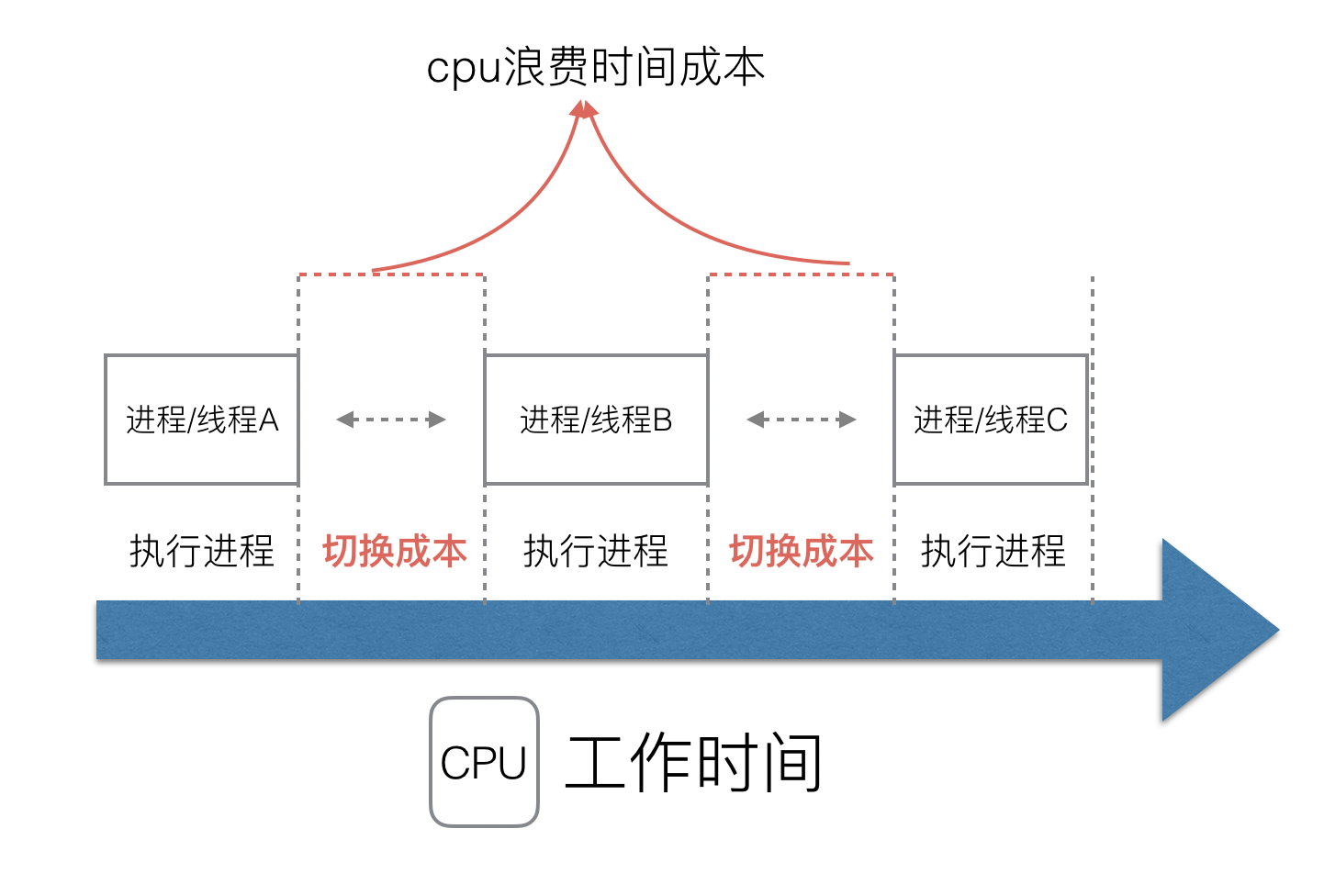
怎么才能提高CPU的利用率呢?
对于Linux操作系统来讲,CPU 对进程的态度和线程的态度是一样的:CPU 调度切换的是进程和线程。尽管线程看起来很美好,但实际上多线程开发设计会变得更加复杂,要考虑很多同步竞争等问题,如锁、竞争冲突等。
协程时代
多进程/线程已经提高了系统的并发能力,但是在当今互联网高并发场景下,为每个任务都创建一个线程是不现实的,因为会消耗大量的内存(进程虚拟内存会占用4GB[32位操作系统], 而线程也要大约4MB)。
大量的进程/线程出现了新的问题
- 高内存占用
- 调度的高消耗CPU
好了,然后工程师们就发现,其实一个线程分为“内核态“线程(thread)和”用户态“线程(co-routine)。
一个“用户态”线程必须要绑定一个“内核态”线程
但是CPU并不知道有“用户态线程”的存在,它只知道它运行的是一个“内核态线程”(Linux的PCB进程控制块)。
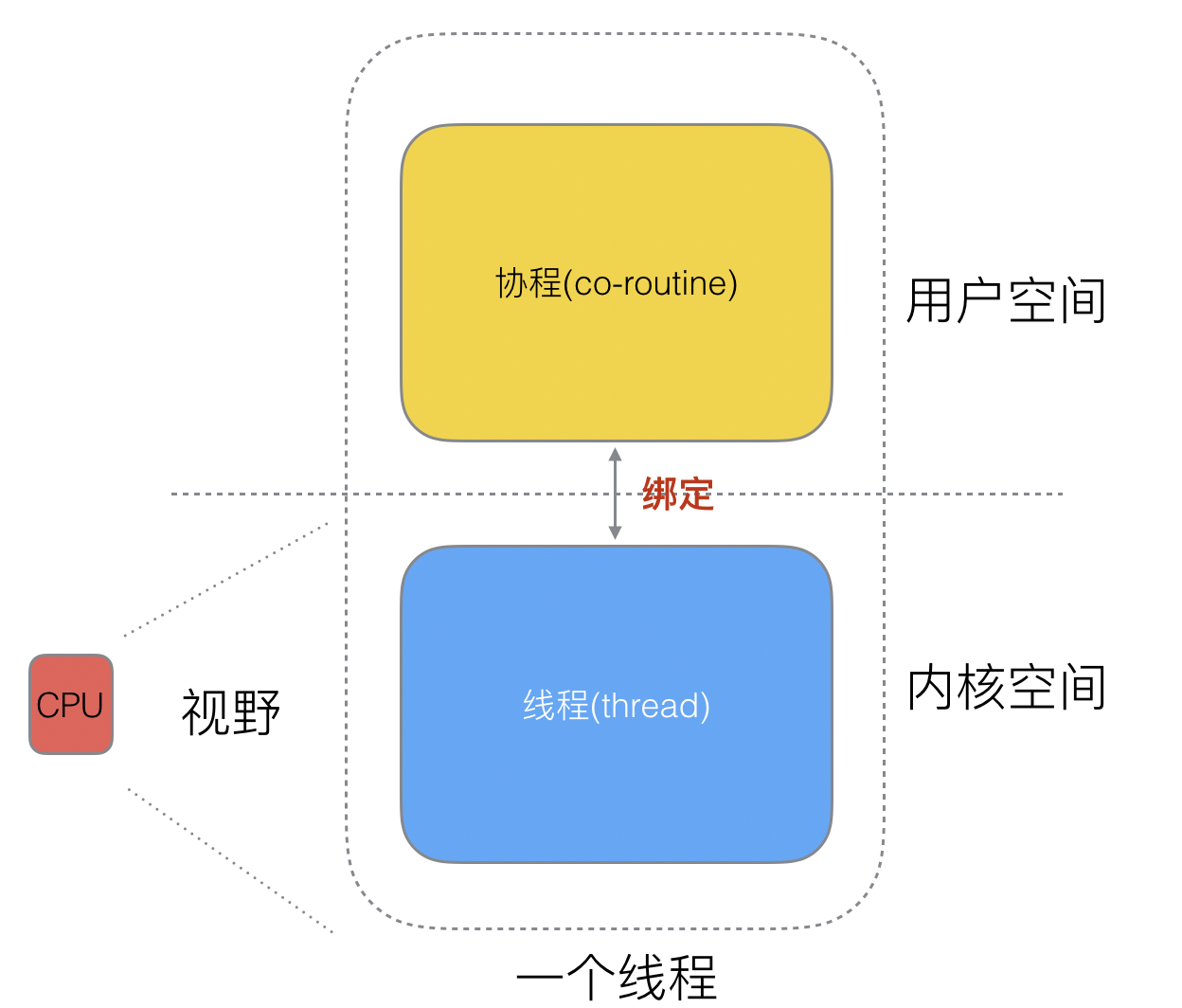
既然一个协程(co-routine)可以绑定一个线程(thread),那么能不能多个协程(co-routine)绑定一个或者多个线程(thread)上呢。
3种协程和线程的映射关系
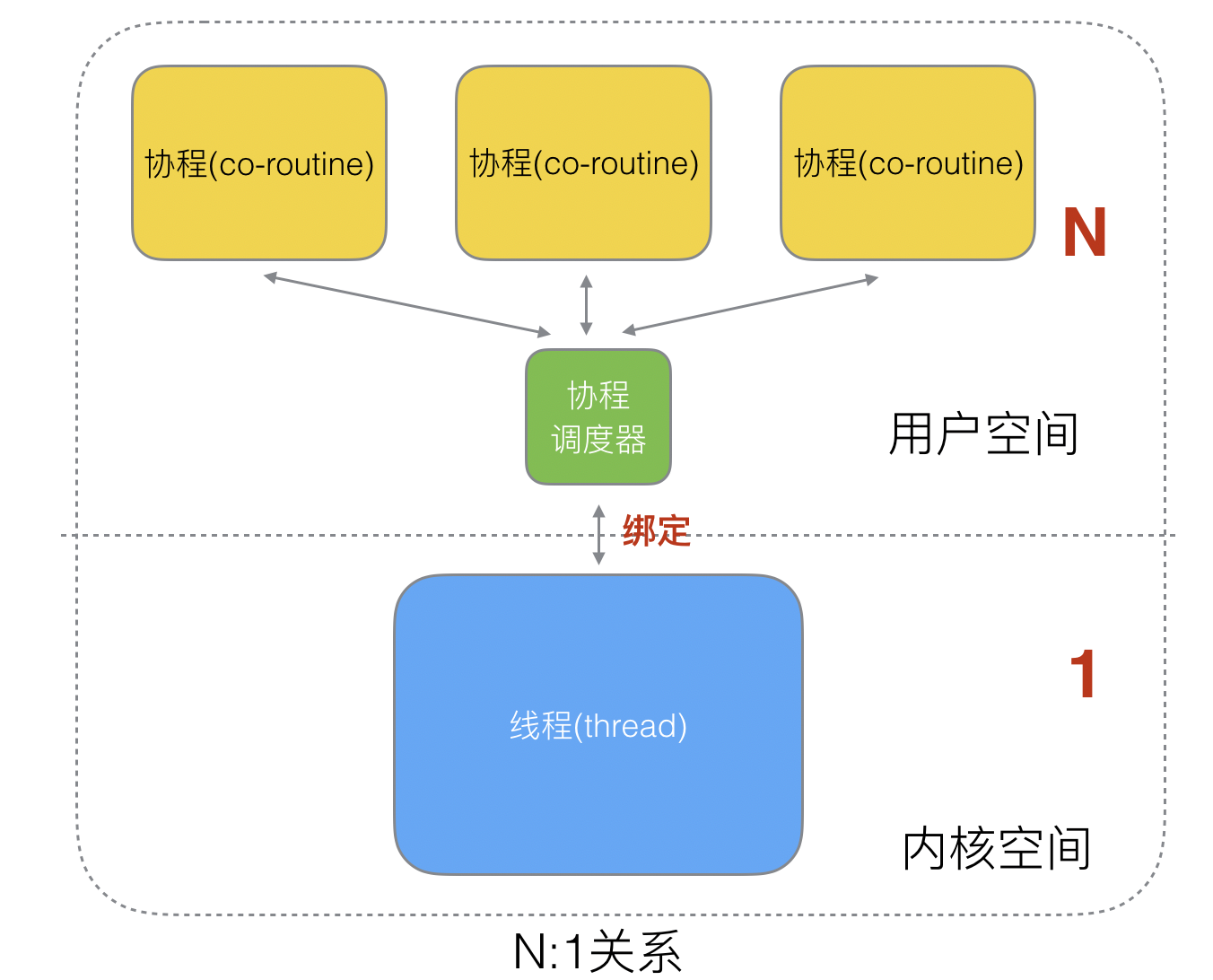
N:1
N个协程绑定1个线程,优点就是协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点:
- 程序无法发挥硬件的多核加速能力
- 一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
1:1
1个协程绑定1个线程,这种最容易实现。协程的调度都由 CPU 完成了,不存在 N:1 的缺点,但也有其缺点:
- 协程的创建、删除和切换的代价都由CPU完成,代价昂贵。
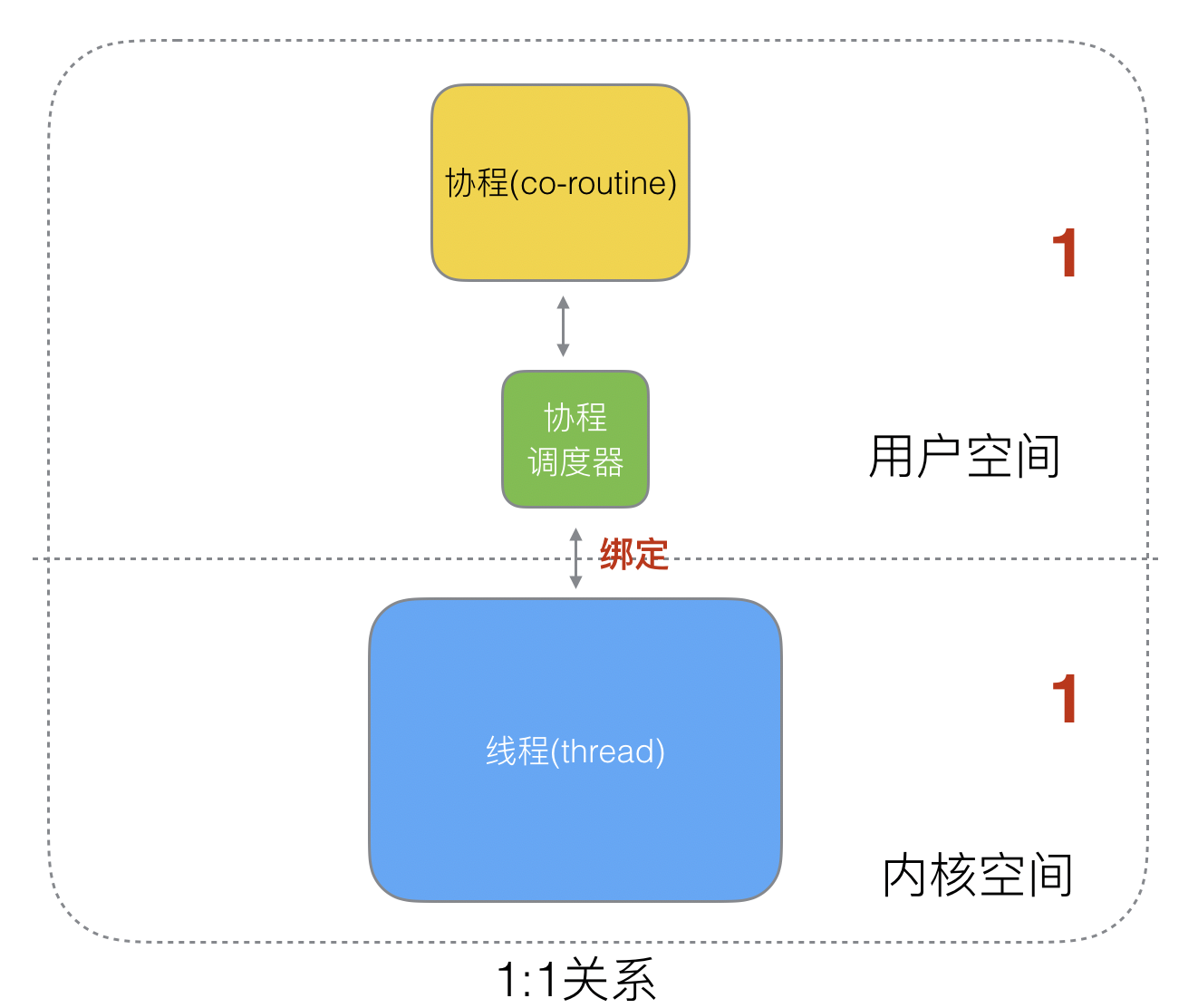
M:N
M个协程绑定1个线程,是N:1和1:1类型的结合,克服了以上2种模型的缺点,但实现起来最为复杂。
协程跟线程是有区别的,线程由CPU调度是抢占式的,协程由用户态调度是协作式的,要等待一个协程主动让出CPU才执行下一个协程,
goroutine:Go语言的协程
Go为了提供更容易使用的并发方法,使用了goroutine和channel。在 Go中,协程被称为goroutine,它让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被runtime调度,转移到其他可运行的线程上。
最关键的是:
程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
Goroutine特点:
- 轻量,占用内存更小(几kb)
- 调度更灵活,并发支持度更高
被废弃的goroutine调度器
Go目前使用的调度器是2012年重新设计的,因为之前的调度器性能存在问题,所以使用4年就被废弃了,那么我们先来分析一下被废弃的调度器是如何运作的?
按照惯例,G来表示Goroutine,M来表示线程
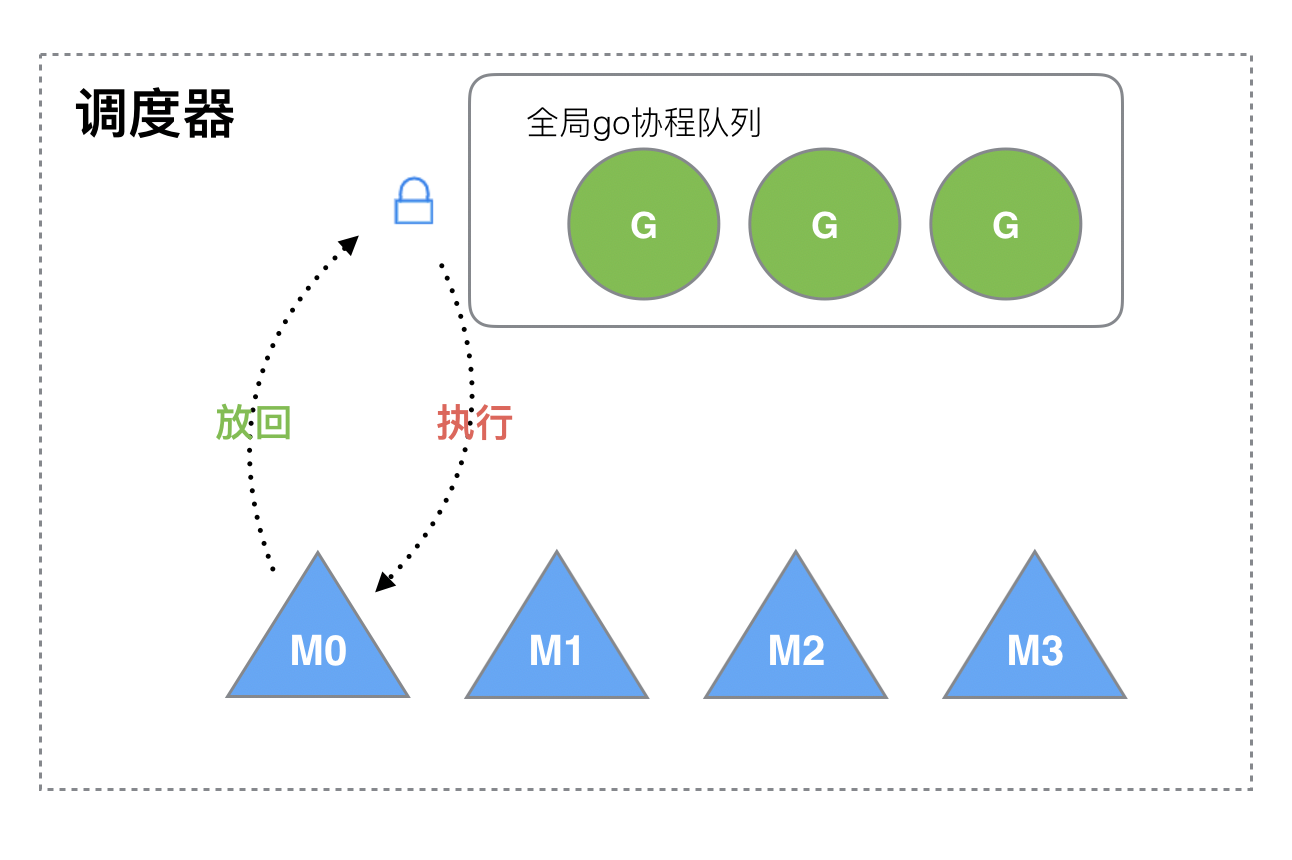
老调度器有几个缺点:
- 创建、销毁、调度G都需要M先获取全局队列的锁,这就形成了激烈的锁竞争。
- M转移G会造成延迟和额外的系统负载。比如当G中包含创建新协程的时候,M创建了G’,为了继续执行G,需要把G’交给M’执行,也造成了很差的局部性,因为G’和G是相关的,最好放在M上执行,而不是其他M’。
- 系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
GMP 模型
面对之前调度器的问题,Go设计了新的调度器,引入了 P(Processor),它包含了运行goroutine的资源以及可运行的G队列,如果线程M想运行G,必须先获取P。
计算机世界里面的任何问题都可以通过增加一个中间层解决。
- G:协程,goroutine
- M:线程,实际运行goroutine的实体
- P:调度器,把可运行的G分配到M上
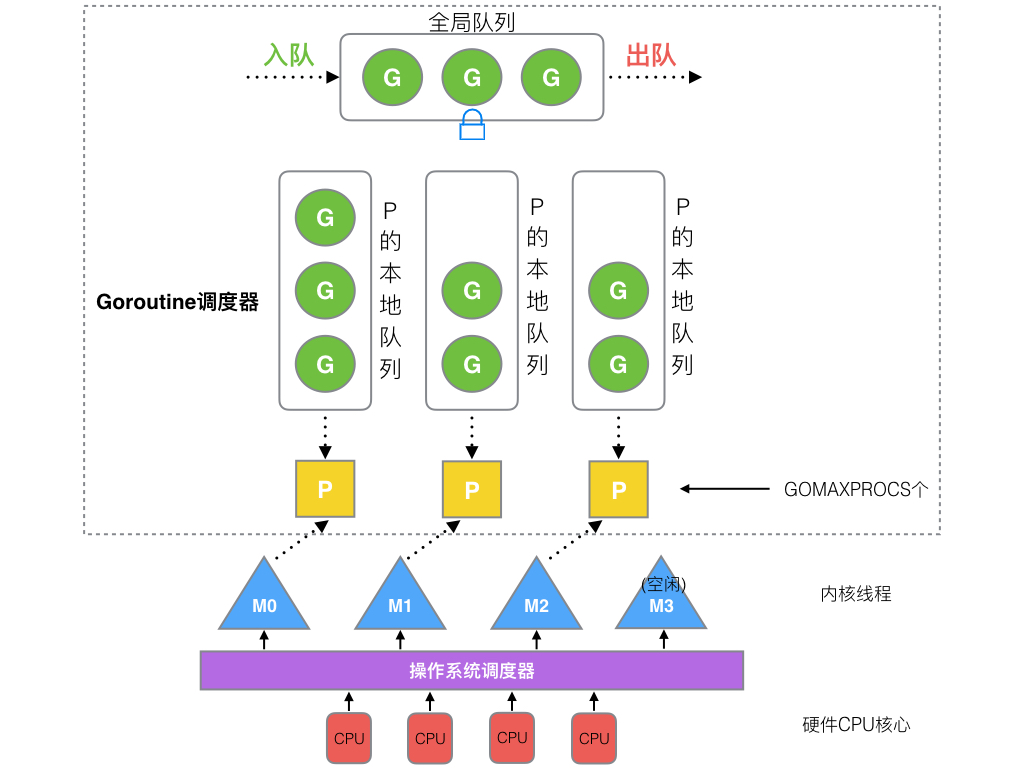
- 全局队列:存放等待运行的G。
- P的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过
256个。新建G’时,G’优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。 - P列表:所有的P都在程序启动时创建,最多有
GOMAXPROCS(可配置)个。 - M:线程想运行任务就得先获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
P和M的数量问题
1、P的数量:
由启动时环境变量$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个goroutine在同时运行。
2、M的数量:
- go语言本身的限制:go程序启动时,会设置M的最大数量,默认
10000,但是内核很难支持这么多的线程数,所以这个限制可以忽略。 runtime/debug中的SetMaxThreads函数,设置M的最大数量
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M。G只能运行在M中,一个M必须持有一个P,M与P至少是1:1的关系。所以:
即使P的默认数量是1,也有可能会创建很多个M出来。
P和M何时会被创建
1、P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
2、M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M。
调度器的设计策略
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
work stealing机制:当本线程无可运行的G时,尝试从全局队列或其他线程绑定的P偷取G,而不是销毁线程。hand off机制:当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
并行:最多有
GOMAXPROCS个线程分布在多个CPU上同时运行,也限制了并发的程度。抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,而在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
全局G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
go func() 调度流程
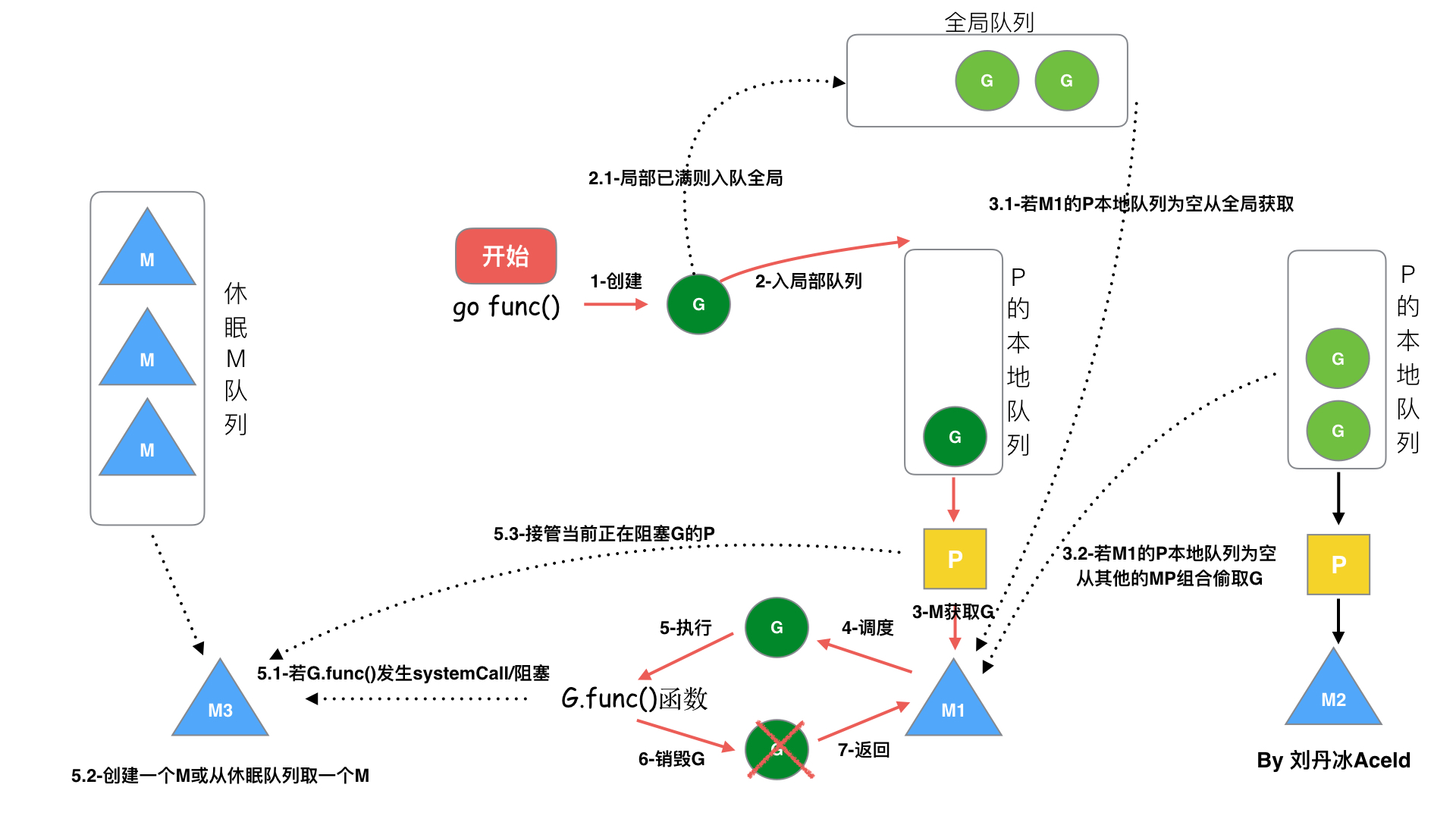
从上图我们可以看出来:
- 每个P有个局部队列,局部队列保存待执行的G(流程2),当M绑定的P的的局部队列已经满了之后就会把G放到全局队列(流程2-1)
- 每个P和一个M绑定,M是真正的执行P中G的实体(流程3),M从绑定的P中的局部队列获取G来执行
- 当M绑定的P的局部队列为空时,M会从全局队列获取到本地队列来执行G(流程3.1),当从全局队列中没有获取到可执行的G时候,M会从其他P的局部队列中偷取G来执行(流程3.2),这种从其他P偷的方式称为
work stealing - 当G因系统调用(
syscall)阻塞时会阻塞M(流程5.1),此时P会和M解绑即hand off,并寻找新的空闲的M,若没有空闲的M就会新建一个M(流程5.2),随后,M会接管当前正在阻塞G的P(流程5.3)。 - 当G因
channel或者network I/O阻塞时,不阻塞M,M会寻找P中其他runnable的G;当阻塞的G恢复后会重新进入P队列等待执行。
调度过程中阻塞
GMP模型的阻塞可能发生在下面几种情况:
- I/O,select
- block on syscall
- channel
- 等待锁
- runtime.Gosched()
用户态阻塞
当goroutine因为channel操作或者network I/O而阻塞时,对应的G会被放置到某个wait队列(如channel的waitq),该G的状态由_Gruning变为_Gwaitting,而M会跳过该G尝试获取并执行下一个G,如果此时没有runnable的G供M运行,那么M将解绑P,并进入sleep状态;当阻塞的G被另一端的G2唤醒时(比如channel的可读/写通知),G被标记为runnable,尝试加入G2所在P的runnext,然后再是P的Local队列和Global队列。
系统调用阻塞
当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于 block on syscall 状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。
调度器的生命周期
特殊的M0和G0
M0
- 启动程序后的编号为
0的主线程; - 在全局变量
runtime.m0中,不需要在heap上分配; - M0负责执行初始化操作和启动第一个G,之后M0就和其他的M一样了。
G0
- 每次启动一个M都会第一个创建的gourtine,
- G0仅用于负责调度的G,
- G0不指向任何可执行的函数, 每个M都会有一个自己的G0,
- 在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。
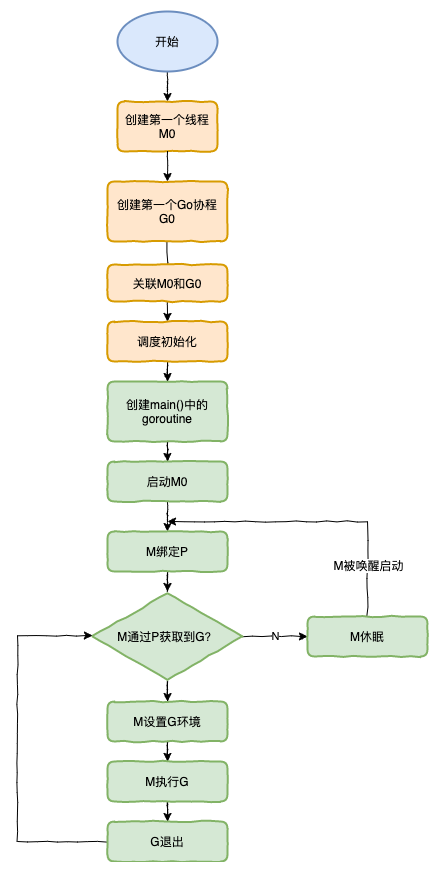
我们来跟踪一段代码:
1 | package main |
结合上图对调度器里面的结构做一个分析:
- runtime创建最初的线程m0和goroutine g0,并把2者关联。
- 调度器初始化:初始化m0、栈、垃圾回收,以及创建和初始化由GOMAXPROCS个P构成的P列表。
- 示例代码中的main函数是main.main,runtime中也有1个main函数——runtime.main,代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建goroutine,称它为main goroutine吧,然后把main goroutine加入到P的本地队列。
- 启动m0,m0已经绑定了P,会从P的本地队列获取G,获取到main goroutine。
- G拥有栈,M根据G中的栈信息和调度信息设置运行环境
- M运行G
- G退出,再次回到M获取可运行的G,这样重复下去,直到main.main退出,runtime.main执行Defer和Panic处理,或调用runtime.exit退出程序。
GMP高效策略
- M是可以复用的,不需要反复创建与销毁,当没有可执行的Goroutine时候就处于自旋状态,等待唤醒
Work Stealing和Hand Off策略保证了M的高效利用- 内存分配状态(mcache)位于P,G可以跨M调度,不再存在跨M调度局部性差的问题
- M从关联的P中获取G,不需要使用锁,是
lock free的
